 ps
ps
How does compiler generation work when a system is composed of many languages? Organizing and specifying systems with interfaces is a well-known software engineering technique. But interfaces, languages, and procedures are all really the same thing [Lampsons-hints]. In this section we examine how multiple languages are assembled into systems and how this impacts compiler generation.
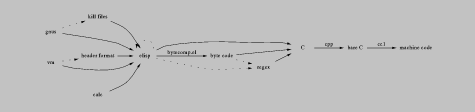
Emacs is a good example of a system with many languages: C code is run through cpp then compiled into machine code. Elisp is compiled into byte-code then interpreted. Regular expression matching is available as an elisp primitive. Modes implement UI languages, and some modes even have full-scale interpreters built in [note emacs-languages-all]. These relationships form a directed graph [this graph isn't quite right. should delete killfiles and header format, dotted edges, but what is elisp's eval?].
Say interpreter int1 has another interpreter int2 as a primop.
int2 is an embedded language. In emacs, this is the relationship
of bytecode to the regexp language. Schematically, the code looks
like this:
int2(prog, data) = ...int1(prog, data) = switch prog case: int2(data1, data2) ...
Now say that for some program p calls int2 with the same data1 again and again, ie there are three stages: prog, data1, and data2. Data1 can be compiled by adding
another case to int1:
int2(prog, data) = ...Herecomp_int2 = cogen(int2, (s d))
int1(prog, data) = switch prog case: comp_int2(data1) case: apply(x, data2) ...
comp_int1 = cogen(int1, (s d)) works fine.
What happens if int1 and int2 are the same? This is reflection. A lisp system's eval is a familiar example. A fixed
point is required to generate the compiler: it is closed because cogen
memoizes on binding times (the table is stored in eval) (note: it
has to look it up in the table every time it is called, here we see
another artifact of direct cogen instead of self-applicataion).
In general, reflective sublanguage relationships form a directed
graph. This graph is lazily traversed by cogen.
Consider a different kind of composition:
int1(prog1, data1) = ...That is,int2_1 = `(some program text)
int2(prog2, data2) = int1(int2_1, (list prog2 data2))
int2_1 is a program written in the language defined
by int1. We say int2 is a layer on top of int1.
Here cogen(int2 (s d)) fails because int2_1 is represented
with data instead of code, so it doesn't get very far as a metastatic
value. So instead write:
comp_int1 = cogen(int1, (s d))Now inobj = comp_int1(int2_1)
int2(prog2 data2) = obj(prog2, data2)
cogen(int2, (s d)) obj is a procedure so it is analyzed
by cogen properly. Since various annotations are required for most
interesting inputs to cogen, obj must in general contain
annotations. These annotations must be created by cogen from int1
and int2_1.
The above is equivalent to using a binding time lattice with multiple stages.